Why ThreadLocal Becomes Dangerous After Moving to Virtual Threads
A practical look at why old thread-bound assumptions break in modern Java concurrency, and what to do instead in real production systems.
Introduction — Why This Even Becomes a Problem
For years, a lot of Java backend systems quietly relied on one assumption: one request comes in, one thread handles it, and anything stored in ThreadLocal stays attached to that flow. That assumption shaped a surprising amount of production code.
Logging context, tenant metadata, security identity, correlation IDs, locale, and custom request-scoped state often ended up in ThreadLocal because it felt simple, cheap, and invisible.
Then virtual threads arrived and changed the scaling model. They made it possible to run a very large number of concurrent tasks without the old cost of one platform thread per request.
That is a huge win. But it also exposes an uncomfortable truth: many Java services were not just using threads for execution, they were using thread identity as part of the application design.
That is where the danger starts. ThreadLocal does not suddenly become invalid.
In fact, it continues to work in enough places that teams assume everything is fine. But once code starts crossing async boundaries, using executors differently, mixing framework-managed context, or relying on inherited state, these assumptions break in subtle ways.The result is not usually a clean failure. It is confusing production behavior.
You might see logs without correlation IDs. You might see security or tenant context missing in downstream operations.
You might see request metadata vanish in background tasks. You might even retain stale state longer than expected because cleanup was tied to a thread lifecycle model that no longer matches how the application now behaves.
So the real lesson here is not “never use ThreadLocal.” The real lesson is that virtual threads force us to re-evaluate old patterns that were safe only because the old execution model hid their weaknesses. If a design depends on thread-bound context for correctness, not just convenience, that design deserves a second look before or during migration.
In the next section, we will look at why ThreadLocal became so popular in Java services in the first place, because understanding that history makes it easier to explain why so many systems still depend on it.
public class RequestContextHolder {
// Store the correlation id in a thread-local variable
private static final ThreadLocal<String> CORRELATION_ID = new ThreadLocal<>();
public static void setCorrelationId(String correlationId) {
// Save the correlation id for the current thread
CORRELATION_ID.set(correlationId);
}
public static String getCorrelationId() {
// Return the correlation id for the current thread
return CORRELATION_ID.get();
}
public static void clear() {
// Remove the correlation id from the current thread
CORRELATION_ID.remove();
}
}
class OrderService {
public void processOrder() {
// Read the thread-local value inside business logic
String correlationId = RequestContextHolder.getCorrelationId();
// Print it to simulate logging or downstream usage
System.out.println("Processing order with correlationId = " + correlationId);
}
}
class DemoApplication {
public static void main(String[] args) {
// Simulate request entry point
RequestContextHolder.setCorrelationId("REQ-12345");
// Call the service
OrderService orderService = new OrderService();
orderService.processOrder();
// Clear the thread-local after request completion
RequestContextHolder.clear();
}
}

Why ThreadLocal Became So Popular in Java Applications
ThreadLocal became popular in Java for a very practical reason: it solved a real engineering inconvenience. In a typical server-side application, one request enters the system, passes through filters, controllers, services, repositories, loggers, and sometimes external clients.
Very quickly, teams need some context to be available everywhere in that request flow. It might be a correlation ID for tracing, a tenant ID for multi-tenant routing, a user identity for security checks, or locale information for formatting and validation.
The obvious alternative is to pass that context explicitly through every method call. That is clean in theory, but in a large enterprise codebase it can become noisy very fast.
A correlation ID that is needed only for logging may still have to appear in controller methods, service signatures, repository helpers, and utility classes. Developers naturally looked for a simpler option, and ThreadLocal felt like the perfect shortcut. Put the value in once at the edge of the request, then read it wherever needed.
That model fit extremely well with the traditional Java server execution style. Application servers, servlet containers, and thread-per-request handling made the request lifecycle feel tightly bound to a single thread.
As a result, ThreadLocal started to feel less like a low-level primitive and more like invisible request scope. Many frameworks and internal platform utilities encouraged this pattern directly or indirectly. MDC for logging is one of the best-known examples, but similar ideas appeared in tenant routing, transaction context, request metadata, and security propagation.
The reason this is important is that teams often did not merely use ThreadLocal as a convenience. Over time, they built real architectural assumptions on top of it.
A logging interceptor assumed the ID would always be there. A repository helper assumed tenant context could be read globally. A security utility assumed user data could be accessed without passing it explicitly. Once these assumptions spread across the codebase, ThreadLocal stopped being a tiny helper and became part of the application’s hidden wiring.
That hidden wiring worked surprisingly well for years because the platform thread model made it look natural. But the safety came from the execution model, not from the abstraction itself.
In other words, ThreadLocal was often “safe enough” because requests were effectively thread-bound. Once that environment changes, the pattern becomes much easier to misuse, and the old convenience starts carrying real operational risk.
That is why virtual thread adoption can feel confusing. Teams are not just changing a concurrency primitive.
They are exposing places where the application confused execution context with business context. And once those two concepts drift apart, bugs start showing up in places that never looked dangerous during code review.
In the next section, we will move from history to the real risk and look at the first important misconception: ThreadLocal still works with virtual threads, but that does not mean it is still a safe design foundation.
The First Misconception — ThreadLocal Still Works, So What Is the Problem?
This is usually the first reaction when teams start discussing this topic: “But ThreadLocal works with virtual threads, right?” And technically, that is true. A virtual thread can have its own ThreadLocal values, and code that sets and reads them may appear to behave correctly in simple examples.
That is exactly why this topic gets missed so often. The failure is not in basic syntax or API support.The failure is in the assumptions teams build around it.
The dangerous misunderstanding is thinking that API compatibility means design safety. A lot of production code does not use ThreadLocal as a tiny local optimization.
It uses it as an invisible context propagation mechanism. That means correctness depends on always setting the right value at the right boundary, reading it only in the expected execution path, and cleaning it up properly afterward.Once ThreadLocal is carrying logging context, user identity, tenant routing, or request metadata, it is no longer just a convenience. It becomes part of the correctness model.
With platform threads, many teams got away with this because the lifecycle was easier to reason about. A request started, a thread stayed associated with that request, and cleanup happened near the end.
With virtual threads, some of the old mental shortcuts stop being reliable. The code may still compile, the application may still run, and many tests may still pass.But hidden context assumptions become more fragile once execution is more lightweight, more concurrent, and often mixed with newer concurrency styles.
Another reason this gets overlooked is that most failures are indirect. You usually do not see “ThreadLocal is broken” in an error message.
Instead, you see missing trace IDs in logs, strange null values in background work, incorrect context in callbacks, or behavior that only appears under specific load conditions. Those symptoms often get blamed on observability tooling, async code, executor configuration, or framework behavior before anyone questions the deeper design choice.
So the real problem is not that virtual threads reject ThreadLocal. The real problem is that they expose how much the system depended on thread-bound state as if it were request-bound state.
Those two ideas are not always the same, and treating them as the same is where production risk starts to grow.
A good way to say this in an interview or article is: ThreadLocal still works at the API level, but virtual threads force us to question whether it still works as an architectural assumption. That is the distinction that matters.
In the next section, we will make this more concrete by looking at the kinds of production issues teams actually see when ThreadLocal-based context is used carelessly in modern Java applications.
What Actually Goes Wrong in Production
This is the part that matters most, because the risks around ThreadLocal are rarely theoretical. Teams usually discover them only after migration work has already started, or worse, after the system has gone live under realistic traffic.
The bugs are often subtle, hard to reproduce, and easy to misdiagnose because nothing looks obviously wrong in the code.
One common issue is missing context in logs. A team expects every request to carry a correlation ID, and local testing looks fine.
But once part of the flow moves through asynchronous execution, background tasks, or framework-managed concurrency, the logging context is no longer guaranteed to appear where it is expected. Suddenly observability becomes unreliable, and that makes every other production issue harder to debug.
Another issue is broken tenant or security context. In many enterprise systems, ThreadLocal is not just used for diagnostics.
It influences actual behavior. A tenant identifier may decide which schema, database, or routing path gets used.A security context may affect authorization checks or downstream calls. If that information is missing, stale, or accidentally read in the wrong place, the result is not just bad logging. It can become a correctness problem.
Cleanup is another area where production pain shows up. ThreadLocal values are easy to set, but teams are often less disciplined about removing them consistently.
In older designs, long-lived thread pools already made this dangerous. In modern applications, the bigger issue is that cleanup assumptions are often implicit.The code “feels” like the value belongs to a request, but in reality it belongs only to a specific thread unless someone explicitly manages it. That gap between intention and implementation is where bugs live.
There is also a code review problem here. ThreadLocal-based logic often looks harmless in isolation.
A helper reads the current tenant. A logger fetches the correlation ID.A utility method pulls user context without changing method signatures. Each individual line looks neat.But the design cost is hidden because the dependency is invisible. Reviewers see clean method signatures and miss that correctness now depends on ambient thread state.
The production symptoms can be messy. Some requests log incomplete metadata.
Some async callbacks lose identity context. Some scheduled jobs accidentally reuse patterns designed only for request flows.Some incidents become almost impossible to trace because the very context used for debugging is the part that disappeared.
That is why this issue deserves attention during virtual thread adoption. The migration itself may not create the problem from nothing, but it often exposes it.
Virtual threads act like a stress test for designs that quietly treated thread-bound state as a general-purpose context model.
In the next section, we will look at one of the most important technical distinctions in this topic: thread-confined data is not the same thing as request-scoped data, even when older systems made them feel identical.
Thread-Confined Is Not the Same as Request-Scoped
This is one of the most important ideas in the whole article. For a long time, many Java systems behaved as if thread-confined data and request-scoped data were basically the same thing.
In older server models, that assumption often seemed true in practice. One request entered the system, one worker thread handled it, and the thread stayed associated with that work from beginning to end. So if a value lived in ThreadLocal, it felt as if it belonged to the request.
But that feeling came from the execution model, not from the meaning of the data. A request is a business concept.
It represents a unit of user or system work moving through the application. A thread is an execution mechanism. It is just one way the runtime chooses to perform that work. Those are not the same layer of abstraction, and treating them as identical is where design trouble begins.
This matters because business context usually needs stronger guarantees than execution context provides. If something is truly request-scoped, the application should know exactly when it begins, where it is valid, how it is passed forward, and when it must stop existing.
That lifecycle should ideally be explicit in the design. But ThreadLocal hides all of that inside ambient state tied to the current thread. It gives easy access, but weak visibility.
Once a codebase relies heavily on that hidden access, the boundaries become blurry. A helper method can read request state without declaring it.
A repository can depend on tenant context without accepting it as input. A logger can fetch correlation metadata without the caller being aware of the dependency.This makes the code feel elegant at first, but it also makes the data flow harder to reason about, test, and migrate safely.
Virtual threads make this distinction more visible because they push teams to think about work as tasks rather than as long-lived thread ownership. And that is actually healthy.
It forces the design question that should have existed all along: is this value truly tied to a thread, or is it tied to a request, task, operation, or business boundary?
If the answer is “request” or “operation,” then storing it only as thread-bound state is often too weak a model. It may still function in some paths, but it does not describe the intent clearly enough.
The system becomes dependent on a runtime detail to carry business meaning.
That is why good modern designs try to separate these ideas. Execution belongs to the runtime.
Business context belongs to the application. Once you say it that way, it becomes much easier to explain why virtual thread migration is not just a performance topic.It is also a design cleanup opportunity.
In the next section, we will make that more concrete with an example of how hidden context propagation starts to fail once code crosses async or task boundaries.
Where It Starts Failing — Async Boundaries, Background Tasks, and Hidden Context Loss
This is where the design problem stops being abstract. As long as execution stays in one predictable flow, ThreadLocal can give the impression that context is safely available everywhere.
But the moment work crosses an async boundary, that illusion starts to crack. The application may still be processing the same business request, but it is no longer guaranteed to be running in the same execution context in the way the code quietly assumed.
Take a common example: a request enters the system, a filter sets a correlation ID in ThreadLocal, and the service layer uses it for logging. So far, everything looks clean.
Then the service submits some work to an executor, schedules a callback, triggers a background task, or uses a framework feature that shifts execution under the hood. At that point, the business operation continues, but the thread-bound state does not automatically follow in the way people expect.
That is the hidden trap. The code that reads the context often sits far away from the code that created it.
A logger, a tenant resolver, or a downstream client helper may simply call a static method and assume the value is there. When it is missing, the failure looks random because the dependency was never explicit.Nothing in the method signature warned the reader that the code required ambient context to function correctly.
This gets even more confusing in real enterprise applications because concurrency is not always obvious. A team may think they are writing straightforward request processing code, but the framework may introduce async dispatch, retries, event callbacks, scheduled work, or task handoff behind the scenes.
That means context loss can appear in places that do not look concurrent at first glance.
The reason virtual thread discussions often surface this issue is that they push teams to revisit how tasks are executed, scheduled, and isolated. And once that happens, hidden ThreadLocal dependencies become easier to notice.
What used to feel like a harmless convenience starts looking like a fragile coupling between business meaning and execution mechanics.
The deeper lesson is simple: if a piece of data must survive across task boundaries, then it is probably not safe to treat it as an invisible property of the current thread. It needs a more explicit propagation model.
Otherwise, the application is depending on execution behavior to preserve business correctness.
That is why async boundaries are such a useful diagnostic tool. They reveal whether context was truly modeled, or merely assumed.
In the next section, we will make this concrete with a small example showing how a correlation ID appears correctly in the main request flow but disappears once the work moves into a separate task.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class AsyncContextLossDemo {
// Store a correlation id in thread-local storage
private static final ThreadLocal<String> CORRELATION_ID = new ThreadLocal<>();
public static void main(String[] args) throws InterruptedException {
// Set the correlation id in the current thread
CORRELATION_ID.set("REQ-9001");
// Print the value in the main flow
System.out.println("Main flow correlationId = " + CORRELATION_ID.get());
// Create a simple executor with one worker thread
ExecutorService executorService = Executors.newSingleThreadExecutor();
// Submit async work
executorService.submit(new Runnable() {
@Override
public void run() {
// Try to read the thread-local inside async work
System.out.println("Async task correlationId = " + CORRELATION_ID.get());
}
});
// Shut down the executor
executorService.shutdown();
// Wait for task completion
executorService.awaitTermination(5, TimeUnit.SECONDS);
// Clear the thread-local from the main flow
CORRELATION_ID.remove();
}
}

Why This Becomes More Dangerous in Real Frameworks
The small example makes the problem visible, but real production systems are usually much more complicated than that. Most teams are not manually creating every thread or every async hop.
They are working inside frameworks like Spring Boot, servlet containers, HTTP clients, messaging listeners, schedulers, and observability libraries. That is exactly why ThreadLocal-related failures become more dangerous in practice: the execution boundaries are often hidden by the framework, while the context assumptions remain hidden in the application code.
A developer may write a perfectly normal service method and assume the request context is available everywhere below it. But somewhere in the flow, the framework may hand the work to another executor, dispatch a callback, trigger a retry, run an interceptor chain, or resume processing in a slightly different execution path.
The business flow still feels like one operation, but the runtime no longer guarantees that the original thread-bound assumptions still hold.
This creates a nasty debugging problem. When ThreadLocal-based context disappears in framework-driven code, it does not look like an application design flaw at first.
It looks like logging broke, tracing broke, the HTTP client lost metadata, or the messaging layer is acting strangely. Teams end up investigating the symptom at the edge instead of the hidden coupling at the center.
Framework abstractions also make dependencies less visible in code review. A helper method reading tenant context from ThreadLocal looks harmless.
A logging interceptor pulling MDC data looks standard. A security utility resolving the current principal from ambient state feels normal because the framework ecosystem has trained people to accept these patterns.But that familiarity is part of the risk. The more “normal” it looks, the easier it is to miss the fact that correctness is now tied to invisible runtime behavior.
This gets even riskier when different infrastructure pieces each manage their own flavor of context. Logging might use MDC.
Security might use its own holder. request metadata might sit in a custom ThreadLocal. A tracing library may propagate context one way, while an internal utility expects it another way.Each piece works in isolation until concurrency boundaries expose the mismatch. Then failures start appearing as partial context loss rather than one clean, obvious break.
That is why real systems often suffer from inconsistent behavior instead of total failure. One part of the stack still sees the right metadata.
Another part loses it. One downstream call includes the trace ID.Another does not. One log line is perfect.The next is missing half the context. These are the hardest production issues to reason about because they look nondeterministic even when the root cause is architectural.
So the big takeaway from frameworks is this: ThreadLocal problems become more dangerous as the platform becomes more helpful. The more execution details the framework hides, the easier it is for hidden context dependencies to survive unnoticed.
In the next section, we will look at one particularly important anti-pattern: using ThreadLocal not just for diagnostics, but as a silent dependency for business-critical behavior like tenant resolution and authorization.
The Most Dangerous Anti-Pattern — Using ThreadLocal for Business-Critical Decisions
Using ThreadLocal for logging context is already risky when concurrency boundaries become less predictable. But using it for business-critical decisions is where the danger becomes much more serious.
At that point, the problem is no longer just missing observability metadata. It becomes a correctness issue, and in some systems it can even become a security or data-isolation issue.
This usually starts innocently. A team wants tenant information to be available across the request flow, so they place it in ThreadLocal.
Or they want to access the current user without passing a security object through every layer, so they read it from a holder. At first this feels elegant.Service methods stay clean. Utility methods can resolve context from anywhere.The code looks less cluttered because business inputs are no longer passed explicitly.
But that neatness comes at a cost. Once a business decision depends on hidden thread-bound state, the method signature stops telling the truth.
A repository method may appear to need only an order ID, but in reality it also depends on tenant context being present. An authorization helper may look stateless, but in reality it expects a user identity to exist in ambient context.A downstream client may appear generic, but it may silently require region, tenant, or compliance metadata to have been set upstream.
That creates a design where the most important dependencies are invisible. And invisible dependencies are exactly the ones most likely to survive code review, evade testing, and fail under concurrency changes.
If a method really cannot operate correctly without a tenant ID or user context, then hiding that requirement inside ThreadLocal is often a form of accidental architectural coupling.
This gets especially dangerous in multi-tenant systems. If tenant resolution is wrong, missing, or stale, the application may not just log incorrectly.
It may query the wrong partition, route to the wrong database, or apply the wrong access rules. Even if the bug is rare, the blast radius is much larger than a missing trace ID.The same logic applies to security-sensitive context. Once identity or authorization depends on implicit state, correctness becomes harder to audit.
One of the clearest warning signs is when teams start describing ThreadLocal as “global for the current request.” That phrase sounds convenient, but it hides the exact problem. It is not truly request-global in a business-safe sense.
It is only thread-local, and the application is choosing to pretend that thread and request mean the same thing.
That is why the anti-pattern is so important to call out. ThreadLocal can sometimes support diagnostics or internal plumbing when used carefully, but when it becomes a silent source of truth for business behavior, the design has crossed into much riskier territory.
In the next section, we will look at how to recognize these hidden dependencies in an existing codebase before they become migration surprises.
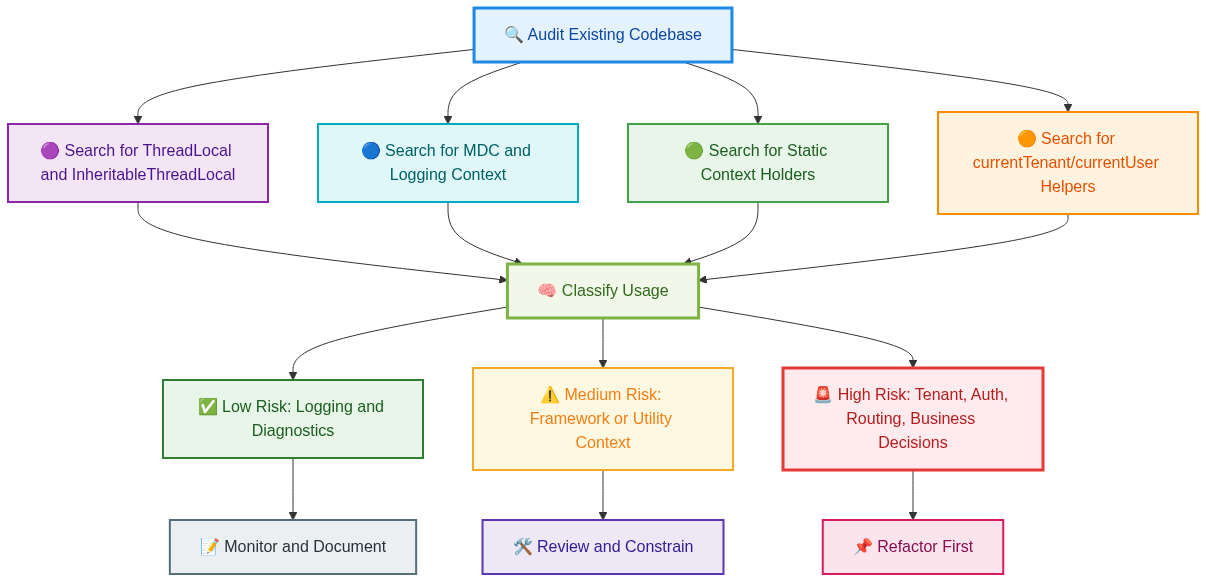
How to Find Hidden ThreadLocal Dependencies in an Existing Codebase
By the time a team starts discussing virtual threads, the biggest risk is usually not the obvious ThreadLocal usage they already know about. It is the usage they have forgotten, normalized, or hidden behind utility layers.
In most mature Java codebases, ThreadLocal does not sit in one neat place with a warning label on it. It spreads through logging helpers, tenant resolvers, request context holders, security utilities, tracing wrappers, and framework glue code.That is why the first practical step is not to redesign everything. It is to make the invisible visible.
A good starting point is to search for direct ThreadLocal declarations, InheritableThreadLocal usage, MDC access, static context holder classes, and helper methods with names like currentTenant, currentUser, requestContext, traceContext, or correlationId. The goal is to map every place where code reads hidden context without accepting it as an explicit input.
Those are the places where the application may be relying on execution state more than the team realizes.
After that, the next step is to classify the usage. Some cases are diagnostic and relatively low risk, like correlation IDs used only for logging.
Some are infrastructural, such as tracing or metrics tags. And some are business-critical, like tenant resolution, region selection, authorization decisions, or downstream routing.That classification matters because not all ThreadLocal usage carries the same blast radius. If a log line loses context, debugging gets harder.If tenant routing loses context, correctness is at risk.
It also helps to trace where the value is written and where it is cleared. A lot of issues come from teams being better at setting ThreadLocal than removing it.
If the lifecycle is not obvious in one place, that alone is a sign that the dependency may be too implicit. You want to know exactly where the value enters the system, which layers read it, whether async boundaries intervene, and who is responsible for cleanup.
One useful mental test is this: if I looked only at the method signature, would I know this method depends on tenant, user, or request metadata to behave correctly? If the honest answer is no, but the method still requires that context through ambient access, then you have found a hidden dependency.
This is also a great place to involve production knowledge. Incident reviews, log inconsistencies, flaky tests, strange async behavior, and tenant-related edge cases often point directly to the most dangerous hidden context paths.
In that sense, migration readiness is not just a code search exercise. It is also an operational archaeology exercise.
The good news is that once these dependencies are identified, teams can make better decisions. Some usages can stay, some can be wrapped more safely, and some should clearly be redesigned.
But none of that is possible until the codebase stops pretending the dependency does not exist.
In the next section, we will look at practical mitigation strategies and discuss when to keep ThreadLocal, when to constrain it, and when to replace it with explicit context propagation.
What to Do Instead — Safer Alternatives to ThreadLocal-Centric Design
Once a team discovers how much hidden behavior depends on ThreadLocal, the next question is obvious: what should we do instead? The answer is not to ban ThreadLocal everywhere without nuance.
The better approach is to choose a context model that matches the importance of the data and the boundaries across which it must survive.
The safest default for business-critical context is explicit propagation. If tenant, user identity, region, or compliance metadata is required for correctness, then passing it through method boundaries is often the clearest design.
Yes, it can make some method signatures longer. But that extra visibility is not noise if the data is genuinely required. It is documentation, correctness, and maintainability expressed directly in code.
For request-scoped diagnostic data, there may still be cases where framework-supported context mechanisms are acceptable, especially if the lifecycle is well understood and the scope is tightly controlled. But even then, teams should prefer well-defined propagation models over ad hoc static holders.
The more important the data is, the less it should depend on invisible ambient state.
Another useful strategy is to separate business context from convenience context. Correlation IDs for logging are not the same category of concern as tenant routing or authorization.
If a correlation ID disappears, debugging becomes harder. If tenant identity disappears, the system may behave incorrectly.Treating both through the same hidden mechanism is what creates avoidable risk. Strong designs use stronger guarantees for stronger responsibilities.
It also helps to narrow where ThreadLocal is allowed at all. Some teams keep it only at framework edges, such as logging decorators or very controlled infrastructure hooks, and explicitly forbid it from becoming a dependency inside business logic.
That kind of rule is valuable because it prevents a low-level convenience from turning into an application-wide hidden contract.
In some cases, structured concurrency and more explicit task modeling can also help teams think more clearly. Once work is treated as a scoped operation rather than a thread-owned journey, it becomes much easier to ask the right question: what context must travel with this operation, and what should remain local to the runtime?
The big idea is simple. If the context matters to correctness, make it visible.
If it is only auxiliary, constrain it carefully. And if a design relies on ThreadLocal because passing the data feels inconvenient, that is often a sign to re-check whether the hidden convenience is worth the long-term risk.
A Modern Alternative Worth Mentioning — ScopedValue
If this article only said “be careful with ThreadLocal,” it would feel incomplete. Modern Java is also moving toward better ways of representing contextual data, and one of the most important ideas worth mentioning here is ScopedValue.
It is not a drop-in replacement for every existing ThreadLocal use case, but it is still highly relevant because it encourages a much healthier model for bounded context.
The biggest difference is conceptual. ThreadLocal is mutable, ambient, and easy to misuse as hidden application state.
A value can be set in one place, read in another, and forgotten entirely during cleanup if the developer is not disciplined. ScopedValue pushes in the opposite direction.It is designed to keep context tightly bounded to a specific execution scope, which makes the lifecycle far more explicit in code.
That explicit boundary is the real advantage. With ThreadLocal, teams often have to remember to set the value, use it correctly, and then remove it manually in a finally block.
In real production code, especially across framework abstractions and async boundaries, that discipline is easy to break. ScopedValue makes the scope visible.The value exists only inside the bounded block where it was attached. That reduces the chance of accidental leakage and makes the code easier to reason about.
There is also a runtime and scalability angle worth mentioning. In very high-concurrency systems, especially the kinds of systems that start benefiting from virtual threads, relying heavily on mutable per-thread context can become more expensive and harder to manage than teams initially expect.
You do not need to turn this into a benchmark claim, but it is fair to say that modern Java is moving toward lighter, more bounded, and less error-prone context models for a reason.
The point here is not that every team should rewrite all ThreadLocal usage immediately. Many enterprise applications still depend on framework integrations, MDC, security holders, or existing platform conventions that cannot be replaced overnight.
But from an architectural standpoint, ScopedValue is worth calling out because it reflects the broader lesson of this article: if context matters, its lifetime and boundaries should be visible, not hidden behind ambient mutable state.
A very small comparison makes this clearer. In the old style, the code sets a ThreadLocal value, runs the business logic, and then relies on manual cleanup.
In the newer style, the context is attached only for the duration of the operation itself. That is a much safer mental model.
import java.lang.ScopedValue;
public class ScopedValueComparison {
// Traditional mutable thread-bound context
private static final ThreadLocal<String> TENANT_THREAD_LOCAL = new ThreadLocal<>();
// Modern bounded context
private static final ScopedValue<String> TENANT_SCOPED_VALUE = ScopedValue.newInstance();
public void handleWithThreadLocal() {
// Manually attach context to the current thread
TENANT_THREAD_LOCAL.set("tenant-1");
try {
// Execute business logic
processWithThreadLocal();
} finally {
// Manual cleanup is required
TENANT_THREAD_LOCAL.remove();
}
}
public void handleWithScopedValue() {
// Bind the value only within this specific execution scope
ScopedValue.where(TENANT_SCOPED_VALUE, "tenant-1").run(new Runnable() {
@Override
public void run() {
// Execute business logic inside the bounded scope
processWithScopedValue();
}
});
}
private void processWithThreadLocal() {
// Read the value from ThreadLocal
String tenant = TENANT_THREAD_LOCAL.get();
// Print the current tenant
System.out.println("ThreadLocal tenant = " + tenant);
}
private void processWithScopedValue() {
// Read the value from ScopedValue
String tenant = TENANT_SCOPED_VALUE.get();
// Print the current tenant
System.out.println("ScopedValue tenant = " + tenant);
}
public static void main(String[] args) {
// Create the demo object
ScopedValueComparison demo = new ScopedValueComparison();
// Run the ThreadLocal example
demo.handleWithThreadLocal();
// Run the ScopedValue example
demo.handleWithScopedValue();
}
}
The code difference is small, but the design difference is meaningful. The ThreadLocal version depends on discipline: set the value correctly, make sure every code path cleans it up, and hope nobody treats it like global hidden state.
The ScopedValue version is more explicit. The context is available only where it is intentionally bound, which makes misuse harder and reasoning easier.
There is also a practical scalability reason this matters. In systems pushing very high concurrency, widespread use of mutable per-thread context can add more overhead and lifecycle complexity than teams expect.
ScopedValue aligns better with the broader goals of modern Java concurrency by encouraging bounded, immutable-style contextual access instead of open-ended thread-attached state.
Conclusion — Virtual Threads Did Not Break ThreadLocal, They Exposed It
The most important takeaway from this article is not that ThreadLocal suddenly became invalid once virtual threads arrived. At the API level, ThreadLocal still works.
That is precisely why this topic is so easy to underestimate. The danger is not in obvious breakage.The danger is in continuing to treat thread-bound state as if it were a safe general-purpose model for request context, business context, or operational correctness.
For years, many Java systems got away with that shortcut because the traditional execution model made the coupling feel natural. One request often mapped cleanly to one worker thread, so hidden context seemed reliable enough.
But that reliability came from the runtime model, not from the design itself. Virtual threads do not create the hidden dependency.They simply remove some of the illusion that made it feel harmless.
That is why this topic matters beyond performance. A virtual thread migration is not just a concurrency upgrade.
It is also a design review opportunity. It pushes teams to ask whether context is truly modeled in the application, or merely stored in places that happened to work under older assumptions.And that is a healthy question, because systems are easier to scale, debug, test, and evolve when their important dependencies are visible.
If the context matters only for auxiliary concerns, then teams should constrain it carefully and understand its lifecycle well. If it matters for correctness, tenant isolation, security, or routing, then it deserves stronger treatment than hidden ambient state.
That distinction is what separates a convenient shortcut from a long-term production risk.
So the final lesson is simple: virtual threads did not really make ThreadLocal dangerous. They made it harder to ignore where it was already being used as an architectural crutch.