Building a Zero-Trust Service Mesh for Spring Boot Microservices: mTLS, RBAC, Policy Enforcement, and Real-World Debugging !!!
Introduction
Over the last few years, I have worked on Java-based microservices in cloud-native environments where service-to-service communication kept growing more complex as the number of internal APIs increased. One pattern I noticed repeatedly was that many teams focused heavily on securing ingress traffic, but once requests entered the cluster, internal service communication was often trusted too broadly. That model worked for speed early on, but it created unnecessary risk, especially in systems where multiple services handled customer, operational, or transaction-sensitive data.
In this context, zero trust follows a simple principle: never trust implicitly, always verify explicitly. In a microservice environment, that means identity becomes the security boundary, not just the network.A service should not be trusted merely because it is running inside the same cluster. Every request between services should be authenticated, encrypted, and authorized based on verified identity and clearly defined policy.
In one of my recent explorations, I wanted to approach this differently and build a more practical zero-trust setup for Spring Boot microservices. The goal was simple in theory: no service should automatically trust another service just because it is inside the network.
Every call should be authenticated, encrypted, and authorized explicitly. Instead of pushing all of that logic directly into application code, I explored implementing it through a service mesh using mTLS, role-based access control, and policy-driven traffic enforcement.
In this article, I’ll walk through how I structured that setup end to end using Spring Boot microservices with a service mesh layer, how I enabled mutual TLS between services, how I applied authorization policies, what the YAML configuration looked like, and what kinds of debugging issues showed up in practice. I’ll also cover a few mistakes and operational lessons that became obvious only after testing the setup under realistic service-to-service traffic flows.
Problem Context and Why Zero Trust Was Needed
Before moving into the implementation, I first wanted to define the actual security gap in a typical Spring Boot microservice setup. In many environments, security is handled properly at the edge through an API gateway, external TLS, and authentication for incoming users.
But once a request enters the internal cluster, service-to-service communication is often trusted too broadly. That approach may feel convenient in the beginning, but it becomes risky as the number of services and internal APIs increases.
In a growing microservice architecture, internal trust boundaries tend to become unclear over time. One service may call two downstream services, those services may call several more, and eventually the platform becomes a dense web of internal communication.
If the environment still assumes that anything inside the network is safe, then a single compromised service, a bad deployment, or an overly permissive internal API can create a much larger exposure than expected. The issue is not only unauthorized external access.The issue is excessive internal trust.
I also noticed that internal security controls are often implemented inconsistently when they are left entirely to individual services. Some services validate tokens thoroughly, some rely on headers passed from upstream calls, and some expose internal endpoints under the assumption that only known callers can reach them.
None of those choices may look severe in isolation, but together they create a model where internal access is not enforced in a uniform or verifiable way.
That was the main reason I wanted to apply a zero-trust approach to Spring Boot microservices. The idea was straightforward: no service should automatically trust another service simply because both happen to run inside the same cluster.
Every service-to-service call should be authenticated, encrypted, and authorized explicitly. Instead of depending only on application-level conventions, I wanted those guarantees to be enforced consistently at the platform level.
A service mesh made that possible in a much cleaner way. It allowed me to establish workload identity, secure communication using mutual TLS, and apply authorization rules between services without forcing every application team to reimplement the same transport-level security logic in business code.
The Spring Boot services could continue focusing on domain logic and user-facing behavior, while the infrastructure layer handled secure service identity and communication policies in a standardized way.
So the real problem I was solving was bigger than encryption alone. I wanted to reduce implicit trust inside the cluster, standardize how services proved their identity, and control which services could talk to each other.
In other words, I wanted internal communication to follow the same security discipline that teams usually expect at the external boundary.
Target Architecture and Design Decisions
Once the problem was clear, the next step was to decide where the security responsibilities should live. I did not want every Spring Boot microservice to implement certificate handling, mutual authentication, and service-to-service authorization separately in application code.
That approach usually creates duplication and inconsistency across services. Instead, I wanted a model where the platform could enforce identity, encryption, and access rules in a standard way, while the microservices continued focusing on business logic.
That is where the service mesh became the right fit. For this implementation, I used Istio as the service mesh control plane, although the same architectural principles can be applied with other service mesh technologies such as Linkerd depending on operational preferences and feature requirements. I used the mesh layer to manage transport security and workload identity so that communication between services could be secured without changing every application in a custom way.
Each Spring Boot service still remained responsible for domain validation, request processing, and user-level authorization where needed, but the trust model between workloads moved into the infrastructure layer. This separation made the architecture cleaner and reduced the chance of security behavior drifting from one service to another.
At a high level, the architecture consisted of an ingress layer, a service mesh layer, a set of Spring Boot microservices, and an observability layer. External traffic first entered through an ingress gateway.
From there, requests were routed into internal services running inside Kubernetes. Each service had a sidecar proxy, and all service-to-service communication flowed through those proxies.That design allowed the mesh to enforce mutual TLS transparently and apply policies based on verified workload identity instead of relying on loosely trusted internal headers or source locations.
One important design choice was to keep authorization layered. The service mesh handled workload-level security, which meant deciding whether one service was allowed to call another service or access a particular internal route.
The application itself still handled business authorization, such as whether a specific user was allowed to approve a transaction or access a customer record. I preferred this split because the mesh is strong at enforcing communication boundaries, while the application should remain the source of truth for business decisions.
Another design decision was to support gradual rollout. In real systems, turning on strict zero-trust controls all at once can break traffic very quickly, especially if some services are still making undocumented or overly broad internal calls.
So I wanted an architecture that allowed a phased path: first observe traffic patterns, then enable secure transport, and finally tighten authorization rules step by step. That made the rollout more realistic and easier to debug.
I also treated observability as a core part of the architecture, not something to add later. When authorization policies block traffic or mTLS is misconfigured, the failure symptoms often appear as generic connection errors, timeouts, or denied requests.
Without clear metrics, logs, and traces, those issues become difficult to diagnose. So from the beginning, I assumed that visibility into the mesh and service behavior was essential to making zero-trust practical in production.
Architecture Diagram
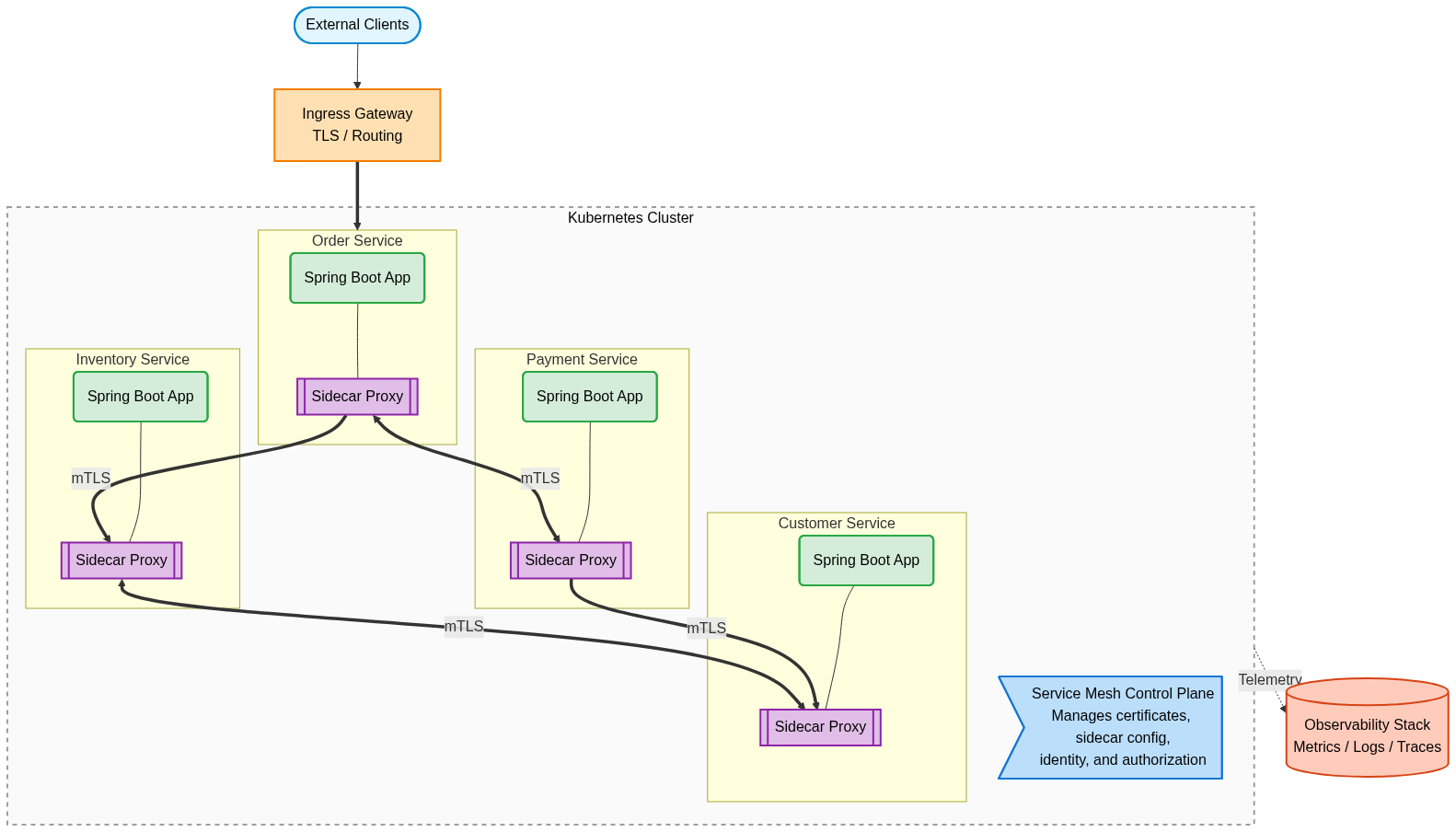
Key Design Decisions
Enforce service identity at the mesh layer instead of trusting the internal network.
Secure all service-to-service communication using mutual TLS.
Keep business authorization inside Spring Boot services.
Use centralized policies for workload-level access control.
Roll out controls gradually instead of switching to strict enforcement in one step.
Treat observability as a mandatory part of the solution.
Enabling Mutual TLS Between Microservices
After defining the target architecture, the first implementation step was enabling mutual TLS for service-to-service communication. This was one of the most important parts of the setup because zero trust starts with strong identity and encrypted communication between workloads.
I did not want services to talk to each other over plain internal traffic, and I also did not want identity to depend on assumptions like namespace location or source IP. Each service needed to present a verifiable identity, and each connection needed to be encrypted by default.
This is where the service mesh added a lot of value. Instead of making every Spring Boot service manage certificates, trust stores, and TLS handshakes directly in application code, the mesh handled those responsibilities through sidecar proxies.
That meant the services could continue communicating normally over HTTP within the container context, while the proxies established secure mTLS connections between workloads behind the scenes. The result was much cleaner from a development standpoint and much more consistent from an operational standpoint.
The key benefit of mTLS in this model was that it provided both encryption and mutual authentication. Encryption protected traffic from being read in transit, even inside the cluster.
Mutual authentication ensured that the calling service and the receiving service could verify each other’s identity before any request was accepted. That changed the trust model completely.Instead of assuming internal traffic was safe, each service-to-service call had to prove who it was at the transport layer.
For rollout, I preferred enabling this in stages rather than switching everything to strict mode immediately. In a real environment, some services may still communicate in ways that are not fully documented, and forcing strict mutual TLS too early can break important traffic paths without enough visibility into why.
A gradual rollout allows the platform team to observe traffic, confirm sidecars are injected correctly, verify certificate distribution, and then move toward full enforcement once the communication patterns are understood.
Another lesson I learned early was that mTLS issues rarely present themselves in a very obvious way. The application may only show generic timeouts, connection resets, or 503-style errors, while the actual problem sits in sidecar configuration, certificate issuance, or policy mismatch.
Because of that, I treated observability as part of the mTLS rollout itself. It was not enough to turn on secure communication; I also needed a reliable way to validate that the mesh was encrypting traffic correctly and that workloads were authenticating each other as expected.
Once mTLS was enabled successfully, the environment moved from “services can talk because they are inside the cluster” to “services can talk because they have a verified identity and a secure channel.” That was the foundation required before introducing stricter authorization controls.
Example Peer Authentication Policy
This kind of policy is what enables strict mutual TLS for workloads in a namespace:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: production
spec:
mtls:
mode: STRICT
This tells the mesh that workloads in the production namespace should only accept mutual TLS traffic. In other words, plain traffic is no longer allowed for service-to-service communication inside that namespace.
Example Destination Rule
To make sure clients also use mutual TLS when calling downstream services, a destination rule can be applied like this:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: default-mtls
namespace: production
spec:
host: "*.production.svc.cluster.local"
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
This configures service calls within that namespace to use the certificates managed by the service mesh.
Practical Checks During Rollout
Confirm that sidecar proxies are injected into all target pods.
Verify that services can still communicate before moving to strict enforcement.
Check mesh certificates and workload identity mapping.
Review proxy logs when requests fail with connection or handshake errors.
Use metrics and traces to confirm encrypted traffic is flowing as expected.
Enable strict mode only after validating that all critical paths are mesh-aware.
Applying Authorization Policies and RBAC
Once mutual TLS was in place, the next step was to control which services were actually allowed to talk to each other. mTLS solved the problem of secure communication and verified service identity, but it did not decide whether a request should be permitted. A zero-trust model needs both pieces. First, every service must prove who it is. Second, that identity must be checked against an explicit access policy before the request is allowed.
This was the point where authorization policies and role-based access control became important. I wanted to move away from a model where any authenticated internal service could call any other service freely. Instead, access needed to be restricted based on the actual role of the calling workload. For example, an order service might be allowed to call inventory and payment services, but it should not automatically have access to customer administration endpoints or internal management APIs that were outside its responsibility.
The service mesh made this much easier because authorization could be defined centrally using workload identity and request-level attributes. Rather than hard-coding all service-to-service trust rules inside every Spring Boot application, I could define clear policies that allowed specific callers to reach only specific destinations, methods, or URL paths. That gave me a much more maintainable model because the communication boundaries were visible as policy instead of being hidden across many services.
I also found it useful to think about authorization in layers. At the mesh layer, the goal was to answer questions like: which service can call which other service, on what path, and using which HTTP methods. At the application layer, the goal remained different: which user is allowed to perform which business action. That distinction helped keep responsibilities clean. The mesh enforced workload-to-workload trust boundaries, while the Spring Boot service still enforced domain-specific permissions.
A practical rollout pattern was to start with deny-by-default thinking, but apply it carefully. If policies are too strict too early, real traffic can break in ways that are hard to trace. So I usually preferred to first understand the actual communication patterns, then apply targeted allow rules for legitimate traffic, and then tighten access gradually. The key idea was that service access should become intentional, not accidental.
One of the biggest benefits of this approach was reducing blast radius. Even if one service was compromised or misused, it would not automatically gain broad access to the rest of the system. It could only reach the destinations and routes that were explicitly permitted by policy. That is a much stronger internal security model than simply encrypting traffic and assuming authenticated callers should be trusted everywhere.
Example Authorization Policy
The following example allows only the order-service workload to call specific endpoints on the inventory-service:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: inventory-service-policy
namespace: production
spec:
selector:
matchLabels:
app: inventory-service
rules:
- from:
- source:
principals:
- cluster.local/ns/production/sa/order-service
to:
- operation:
methods: ["GET", "POST"]
paths: ["/api/inventory/*"]
This policy means that only the workload identity associated with order-service is allowed to call the inventory service on the listed API paths using the allowed HTTP methods.
Another Example for Restricting Admin Access
If I wanted to ensure that only an internal admin service could access sensitive endpoints, I could apply a policy like this:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: customer-admin-policy
namespace: production
spec:
selector:
matchLabels:
app: customer-service
rules:
- from:
- source:
principals:
- cluster.local/ns/production/sa/admin-service
to:
- operation:
methods: ["GET", "POST", "PUT", "DELETE"]
paths: ["/api/admin/*"]
This prevents ordinary internal services from calling sensitive administrative routes unless they are using the expected workload identity.
Practical Policy Design Principles
Allow only the service identities that genuinely need access.
Restrict access by HTTP method and path wherever possible.
Keep workload-level authorization in the mesh and business authorization in the application.
Apply policies gradually and validate real traffic before tightening further.
Use observability tools to understand why requests are allowed or denied.
Avoid broad wildcard access unless there is a very strong operational reason.
Spring Boot Integration and Application-Level Considerations
Once the mesh was handling transport security and workload-level authorization, the next question was how much needed to change inside the Spring Boot services themselves. One thing I wanted to avoid was overloading the application with low-level certificate and mutual TLS handling that the mesh was already solving.
If the sidecar proxies were responsible for secure service-to-service communication, then the application should not duplicate the same transport concerns unnecessarily. That kept the service code cleaner and made the overall architecture easier to maintain.
At the same time, zero trust does not mean the application becomes security-agnostic. The Spring Boot services still needed to handle business-level concerns carefully.
User authentication, domain-specific authorization, request validation, secure error handling, and audit-sensitive logic still belonged in the application layer. The mesh could establish which service was calling another service, but it should not replace the application’s responsibility to decide whether a user is actually allowed to perform a given business action.
In practice, this created a useful separation of concerns. The mesh validated workload identity and enforced secure communication between services.
The Spring Boot application focused on user identity, business permissions, and domain rules. For example, a payment service might trust that a request from the order service came from a legitimate workload because the mesh already enforced that. But the payment service would still need to verify whether the request payload was valid, whether the transaction state allowed the operation, and whether the acting user or business process had the correct permissions.
In some cases, the mesh can also take on a limited part of user-facing security by validating JWT signatures at the edge or service boundary before traffic reaches the Spring Boot service. That can help reduce repeated token validation overhead across services.
Even in that model, I would still keep business authorization and domain-specific access control inside the application, since those decisions usually depend on business rules rather than transport or identity enforcement alone.
Another thing I paid attention to was propagation of request context. Even though service-to-service trust was now enforced at the infrastructure level, application tracing and audit flows still needed correlation identifiers, user context where appropriate, and structured logging.
Without that, debugging cross-service behavior becomes difficult, especially once requests travel through multiple services and proxies. So the mesh improved transport security, but the application still needed disciplined observability practices to remain operable.
I also found it important to review actuator endpoints, internal admin routes, and service-to-service API boundaries inside the Spring Boot applications. A service mesh can enforce strong communication rules, but if a service exposes unnecessary endpoints or mixes internal and external concerns poorly, the risk does not disappear.
The application should still present a minimal and deliberate API surface.
One practical benefit of this model was that most of the application code could remain unchanged during the early phases of mesh adoption. Existing Spring Boot services did not need to be rewritten just to start benefiting from mutual TLS and workload-level access control.
That made the rollout much more realistic. Teams could gain stronger internal security posture without forcing every service owner to redesign application code at the same time.
Example Spring Boot Security Considerations
A few areas I would still review at the application layer were:
Validate incoming request payloads strictly.
Keep user authentication and business authorization inside the service.
Avoid trusting internal headers unless they are controlled and verified.
Disable or secure sensitive actuator endpoints.
Use structured logging and correlation IDs for tracing request flow.
Separate internal APIs from external APIs clearly where possible.
Example Controller
This is a simple example of how the application can stay focused on business behavior while the mesh handles service-to-service security outside the code.
1@RestController // Marks this class as a REST controller
@RequestMapping("/api/orders") // Base path for order APIs
public class OrderController { // Declares the controller class
private final OrderService orderService; // Holds the business service dependency
public OrderController(OrderService orderService) { // Constructor for dependency injection
this.orderService = orderService; // Assigns the injected service
} // Ends the constructor
@PostMapping // Handles HTTP POST requests
public ResponseEntity<String> createOrder(@RequestBody OrderRequest request) { // Accepts an order request body
orderService.createOrder(request); // Delegates business processing to the service layer
return ResponseEntity.ok("Order created successfully"); // Returns a success response
} // Ends the method
@GetMapping("/{id}") // Handles HTTP GET requests for a specific order
public ResponseEntity<OrderResponse> getOrder(@PathVariable String id) { // Accepts the order id from the path
OrderResponse response = orderService.getOrder(id); // Fetches order details from the service layer
return ResponseEntity.ok(response); // Returns the order response
} // Ends the method
} // Ends the controller class
This keeps the controller logic focused on request handling and business flow, while the mesh manages encrypted and authenticated communication between workloads outside the application.
Multi-Tenancy Considerations in a Zero-Trust Service Mesh
Once the core zero-trust model was working, the next layer I would think about is tenancy. In many enterprise systems, especially SaaS-style platforms, security is not only about whether one service can call another service.
It is also about making sure tenant data, tenant context, and tenant-specific access boundaries are preserved correctly across the entire request path. That means a zero-trust architecture should not stop at service identity alone.It also needs to make sure that tenant isolation is handled carefully at both the infrastructure and application layers.
One important thing I would not do is assume that service-level mTLS automatically solves tenant isolation. Mutual TLS proves the identity of the calling workload, but it does not tell us which business tenant the request belongs to.
A service may be fully authenticated at the mesh layer and still process the wrong tenant’s data if tenant context is not validated properly in the application flow. So for me, tenancy remains an application responsibility even when the mesh is handling service-to-service trust.
In practice, I like to treat tenancy as a separate axis of control. The service mesh answers the question, “Is this workload allowed to talk to that workload?” The application answers the question, “Is this request operating within the correct tenant boundary?” That distinction is important because workload identity and tenant identity are not the same thing.
One is infrastructure-level trust between services. The other is business-level data isolation.
A common pattern here is to propagate tenant context explicitly through headers or tokens, but to validate it carefully at each service boundary rather than trusting it blindly. For example, an upstream service may pass a tenant identifier such as X-Tenant-ID, but the receiving Spring Boot service should not just accept that value and query data immediately. It should verify that the user, token, or calling business flow is genuinely associated with that tenant and that the current operation is allowed in that tenant scope. This prevents accidental or malicious cross-tenant access caused by weak assumptions between services.
I also prefer to align tenant isolation with data access design. If the system is using a shared database with tenant keys, then every query path needs strong tenant filtering and validation.
If the system uses schema-per-tenant or database-per-tenant models, then routing and connection management also need to preserve tenant boundaries consistently. The mesh can secure transport, but it cannot fix poor tenant isolation inside repositories, caches, or asynchronous processing logic.
Another area that matters a lot is observability. In a multi-tenant platform, logs, traces, and metrics should include tenant-aware correlation where appropriate, but without leaking sensitive tenant data.
That helps during incident debugging because a team can determine whether an issue is isolated to one tenant, one region, or one service interaction path. Without that visibility, tenant-related issues can become very hard to trace across distributed systems.
From an architecture perspective, I think the cleanest model is this: the mesh enforces service trust, the application enforces tenant trust, and the data layer enforces tenant isolation. When those three layers are aligned, the system becomes much more resilient against both accidental cross-tenant leakage and overly broad internal service access.
Practical Multi-Tenancy Principles
Do not treat workload identity as a replacement for tenant validation.
Propagate tenant context explicitly, but validate it at every service boundary.
Enforce tenant isolation consistently in repositories, caches, and async workflows.
Keep service authorization and tenant authorization as separate concerns.
Include tenant-aware tracing and logging without exposing sensitive data.
Review background jobs and event consumers carefully, since cross-tenant mistakes often happen there.
Example Spring Boot Tenant Context Filter
1@Component // Marks this class as a Spring-managed component
public class TenantContextFilter extends OncePerRequestFilter { // Defines a filter that runs once per request
@Override // Indicates that this method overrides the parent implementation
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException { // Defines the filter logic
String tenantId = request.getHeader("X-Tenant-ID"); // Reads the tenant id from the request header
if (tenantId == null || tenantId.trim().isEmpty()) { // Checks whether the tenant id is missing
response.setStatus(HttpServletResponse.SC_BAD_REQUEST); // Sets HTTP 400 status code
response.getWriter().write("Missing tenant identifier"); // Writes an error message in the response
return; // Stops further processing
} // Ends the validation block
TenantContext.setTenantId(tenantId); // Stores the tenant id in a request-scoped context
try { // Starts a try block to ensure cleanup
filterChain.doFilter(request, response); // Continues processing the request
} finally { // Starts the cleanup block
TenantContext.clear(); // Clears the tenant context after request completion
} // Ends the finally block
} // Ends the filter method
} // Ends the filter class
Here, the TenantContext is typically implemented using a ThreadLocal so that the tenant identifier remains available throughout the lifecycle of the current request. That makes it accessible across service, repository, and logging layers during request processing without having to pass the tenant value manually through every method.
This kind of filter is only the starting point. In a real system, I would also validate the tenant against authenticated user claims or trusted token data rather than relying on the header alone.
Debugging Challenges and Real-World Lessons
Once the service mesh, mTLS, authorization policies, and tenant-aware handling were in place, the next major area was debugging. This is the part that usually looks simple in architecture diagrams but becomes very real during implementation.
In a zero-trust setup, failures are often not obvious. A request may fail because of certificate issues, sidecar injection problems, namespace policy mismatches, incorrect service accounts, or authorization rules that are technically valid but operationally too strict.From the application side, many of these issues can look like generic timeouts, 403 errors, 503 errors, or intermittent connection failures.
One of the first lessons I learned was that debugging in a service mesh has to be approached in layers. If a call fails, I do not start by assuming the Spring Boot code is broken.
I first check whether the sidecars are present, whether the source and destination workloads have the expected identities, whether mTLS is actually being used, and whether the policy definitions match the real traffic path. Only after that do I move deeper into application logs and business flow analysis.That layered debugging approach saves a lot of time because many “application failures” in a zero-trust system are actually policy or infrastructure issues.
Another important lesson was that policy rollout needs to be incremental. It is very easy to write an authorization rule that looks logically correct and then discover it blocks a path used by a background scheduler, an internal health dependency, or an async event callback.
In distributed systems, not every communication path is obvious from code alone. Some are indirect and only show up during runtime.Because of that, I found it much safer to observe traffic patterns first, then introduce targeted policies, and tighten rules gradually rather than trying to lock everything down in one step.
I also noticed that service identity configuration matters more than teams often expect. If the wrong Kubernetes service account is attached to a workload, or if workloads are deployed inconsistently across namespaces, authorization policies may fail even though the application code and endpoint paths are correct.
In other words, zero trust makes identity configuration operationally significant. That is a good thing from a security standpoint, but it also means platform discipline becomes much more important.
Observability made a major difference here. Mesh metrics, proxy logs, distributed traces, and structured application logs together gave the clearest picture.
Metrics helped reveal where traffic suddenly dropped or where error rates increased. Proxy logs helped identify handshake or policy-denied events.Traces helped show exactly where a request stopped flowing. Application logs then helped confirm whether the problem was in infrastructure enforcement or actual business logic.Without all four, troubleshooting became much slower and much more guess-based.
A practical takeaway for me was that zero trust should be introduced as an operational capability, not just as a security feature. Teams need dashboards, logging standards, rollout playbooks, and policy review habits in addition to the technical configuration itself.
The architecture is only part of the solution. The day-two support model matters just as much.
Common Issues I Would Watch For
Sidecar proxy not injected into one or more workloads.
Service account mismatch causing authorization policy failure.
Strict mTLS enabled before all workloads are mesh-ready.
Internal health checks or background jobs blocked by narrow policies.
Namespace-level policy affecting services that were expected to remain open.
Confusing generic application errors that actually come from mesh-layer denial.
Practical Debugging Workflow
Confirm the source and destination pods both have sidecars.
Verify the workload identity and service account mapping.
Check whether mTLS is active between the communicating services.
Review authorization policies for path, method, and principal mismatches.
Inspect proxy logs before assuming application failure.
Use traces to identify exactly where the request stops.
Check Spring Boot logs only after validating the mesh layer behavior.
Example of the Kind of Operational Mindset I Used
When a service call failed, I tried not to jump directly into controller or service-layer debugging. I would first ask whether the request even reached the application.
If the answer was no, then the problem was likely in sidecar behavior, identity, or policy enforcement. If the answer was yes, then I could move into normal Spring Boot debugging.That small mindset shift made troubleshooting much more structured and effective.
Production Hardening and Operational Best Practices
Once the zero-trust foundation was working functionally, the next step was making it production-ready. This is where the design moves beyond “it works in a controlled setup” and becomes something that can survive real traffic, frequent deployments, operational mistakes, and evolving service dependencies.
In my view, production hardening is what turns a secure architecture from a good concept into an actually dependable platform capability.
One of the first things I would focus on is rollout discipline. Security controls like strict mTLS and narrow authorization policies should not be enabled across all services at once unless the environment is already very mature.
In a production system, I prefer phased adoption using lower-risk namespaces, non-critical services, or carefully chosen traffic paths first. That way, the team can validate sidecar behavior, workload identity mapping, policy correctness, and observability signals before enforcing the same rules across more critical parts of the platform.
Another important area is certificate and identity lifecycle management. A lot of teams focus on enabling mTLS once, but production stability depends on what happens after that.
Certificate rotation, sidecar restarts, service account discipline, and trust-domain consistency all matter. If identity management is not operationally clean, the system may appear secure but become fragile during routine changes.I like to treat workload identity as a first-class operational concern, not just a one-time configuration detail.
I would also make sure that reliability controls work well with the mesh instead of fighting against it. Timeouts, retries, circuit breaking, and connection pool behavior need to be tuned with awareness of service mesh proxies and policy enforcement.
Otherwise, transient authorization issues or handshake failures can cascade into larger reliability events. Production hardening is not only about stopping unauthorized traffic. It is also about making sure the platform fails in a controlled and visible way when something goes wrong.
Observability becomes even more important at this stage. In production, I want dashboards that show mTLS coverage, request denial rates, policy changes, certificate health, sidecar status, and service-to-service error trends.
Security incidents and operational incidents often overlap in distributed systems, so the visibility model has to support both. If a deployment suddenly increases denied traffic or breaks a critical call path, the team should know quickly and have enough context to identify whether the issue is in application code, policy configuration, or platform identity.
Another practice I consider essential is policy governance. As the number of services grows, authorization rules can become difficult to manage if naming, ownership, and review standards are weak.
I prefer treating policy as code, versioning it properly, reviewing changes through pull requests, and tying policies to service ownership. That makes the security model easier to maintain and reduces the chance of broad, accidental permissions being introduced under pressure.
At the application side, I would still review internal endpoints, actuator exposure, sensitive logs, and request validation regularly. A service mesh adds strong protection around communication, but it does not remove the need for secure application behavior.
Production hardening works best when infrastructure security and application security reinforce each other rather than operating as separate concerns.
Practical Production Hardening Principles
Roll out strict security controls gradually across environments and service groups.
Treat certificate rotation and workload identity management as operational priorities.
Tune retries, timeouts, and circuit breakers with mesh behavior in mind.
Build dashboards for denied traffic, mTLS coverage, and sidecar health.
Manage authorization policies as code with review and ownership.
Keep application-level security hygiene strong even after mesh adoption.
Test failure scenarios, not just happy-path communication.
Examples of What I Would Validate Before Calling It Production Ready
All critical services have sidecars injected consistently.
Mutual TLS is enforced on intended service paths.
Authorization rules match real communication patterns.
Health checks, background jobs, and async consumers still function correctly.
Certificate rotation does not disrupt traffic.
Monitoring can clearly distinguish policy denial from application failure.
Rollback steps exist if a policy change blocks valid production traffic.
Final Takeaways and Closing Thoughts
Looking back at the overall design, the biggest shift for me was moving away from the assumption that internal traffic is automatically trustworthy. That is really the heart of the whole approach.
In a traditional microservice environment, teams often secure the edge well but leave the internal network too open. What this zero-trust model changed was the default assumption.Instead of trusting services because they are inside the cluster, the platform required them to prove identity, communicate securely, and operate within clearly defined access boundaries.
What I found most valuable was that the service mesh allowed these controls to be introduced in a structured way without forcing every Spring Boot service to reimplement the same transport security logic. Mutual TLS established secure and verifiable service identity.
Authorization policies reduced unnecessary internal access. Application code remained focused on business logic, user-level permissions, and tenant-specific rules.That separation made the architecture stronger and also more maintainable.
At the same time, this was not just a story about enabling a few security features. The real lesson was that zero trust in microservices is as much an operational discipline as it is an architectural choice.
Identity management, policy governance, observability, phased rollout, and debugging practices all mattered just as much as the YAML definitions themselves. Without that operational maturity, even a technically correct design can become difficult to support in production.
Another important takeaway was that zero trust should be layered rather than overloaded into one mechanism. The mesh handled workload identity and secure service communication.
The Spring Boot applications handled business validation, user authorization, and tenant-specific behavior. The data layer preserved tenant and domain isolation.That layered model made the security boundaries clearer and avoided the common mistake of expecting one tool or one control plane to solve everything.
If I had to summarize the entire approach simply, I would say this: the goal was not just to encrypt internal traffic, but to make internal trust deliberate. Every service call should happen over a secure channel, from a verified source, to an explicitly permitted destination, with the application still enforcing its own business rules.
That is what made the system more secure, more predictable, and much easier to reason about as it scaled.
In the end, the strongest benefit of this approach was not only tighter security. It was the fact that the architecture became clearer.
Service boundaries were more intentional, communication paths were more visible, and access assumptions were no longer hidden in informal conventions. For a modern Spring Boot microservice platform, that is a very practical step toward building systems that are both secure and operationally manageable.
Backup, Disaster Recovery, and Resilience Considerations
One important area that also needs attention in a production-grade zero-trust microservice platform is backup and disaster recovery. Security and resilience have to work together.
It is not enough to secure service-to-service communication if the platform cannot recover cleanly from data loss, cluster failure, accidental policy rollout issues, or regional outages. In a real enterprise setup, backup strategy has to cover both application data and the operational configuration that makes the environment function correctly.
The first thing I would separate is data recovery from infrastructure recovery. Application databases, object storage, configuration stores, and audit records need their own backup and retention strategy based on business criticality.
At the same time, Kubernetes manifests, mesh policies, deployment definitions, secrets management references, and observability configurations should also be recoverable through infrastructure-as-code and version-controlled deployment pipelines. If the cluster goes down and only the data is recoverable, but the service identities, policies, and routing definitions are not reconstructed correctly, the platform may come back in a broken or insecure state.
For stateful services, I would define recovery objectives clearly. Some systems can tolerate a few minutes of data loss, while others cannot.
That directly affects backup frequency, replication strategy, and cross-region design. In a multi-service architecture, these decisions should not be left vague because services often depend on each other in ways that make partial recovery risky.If one service is restored to a recent state but another comes back from an older snapshot, the result can be data inconsistency and difficult operational cleanup.
Another thing I would pay attention to is policy and identity recovery. In a zero-trust environment, restoring a service is not just about bringing the pod back up.
The workload has to come back with the correct service account, sidecar behavior, certificates, namespace configuration, and authorization rules. If those security controls are missing or partially restored, the system may either fail closed and become unavailable or fail open and weaken the intended trust model.That is why I would always keep mesh and policy configuration under strong version control and automate redeployment as much as possible.
For disaster recovery planning, I prefer regular recovery drills over relying only on documentation. Teams should test whether they can restore critical services, validate that mTLS is still functioning, confirm that authorization policies behave correctly after failover, and verify that tenant isolation and audit logging still hold after restoration.
A backup strategy is only meaningful if the environment can actually be recovered in a predictable and secure way.
I would also make sure observability survives recovery events. During failover or partial restoration, the team needs clear visibility into which services are healthy, which dependencies are degraded, whether policy denials are increasing, and whether traffic is routing correctly.
Disaster recovery is not just about data restoration. It is also about regaining operational confidence quickly.
Practical Backup and DR Principles
Separate data backup strategy from infrastructure and policy recovery strategy.
Keep mesh configuration, deployment manifests, and policies under version control.
Define recovery objectives clearly for each critical service and data store.
Validate that restored workloads come back with correct identity and policy behavior.
Test failover and recovery drills regularly instead of depending only on written plans.
Ensure monitoring and logging remain available during and after recovery events.
Avoid restoring services in a way that creates inconsistent cross-service state.
What I Would Want Covered in a Real Setup
Database backup and point-in-time recovery for critical services.
Cross-region or secondary-cluster recovery strategy where needed.
Version-controlled Istio or mesh policies and Kubernetes manifests.
Secret recovery process without exposing sensitive material manually.
Post-recovery validation for mTLS, RBAC, and service communication.
Clear runbooks for rollback, failover, and partial-service restoration.
Common Mistakes and Anti-Patterns in Zero-Trust Mesh Adoption
One thing that became very clear to me while thinking through this architecture was that adopting a zero-trust service mesh is not only about enabling the right features. It is also about avoiding the wrong implementation patterns.
A lot of teams introduce a service mesh with good intentions, but the rollout becomes painful because security controls are applied too broadly, too early, or without enough visibility into how services really communicate. In practice, the mistakes are often operational and architectural rather than purely technical.
A common mistake is enabling strict mutual TLS across all workloads before confirming that every service is mesh-ready. If some services do not have sidecars injected properly, if a few internal dependencies still bypass the mesh, or if older workloads are not aligned with the new traffic model, communication failures start showing up very quickly.
The problem is not that mTLS is wrong. The problem is trying to enforce it before the platform has enough readiness and observability to support it.
Another anti-pattern is treating the service mesh as a replacement for application security. The mesh can secure service-to-service communication, verify workload identity, and enforce access policies between services, but it does not replace domain validation, user authorization, input validation, or tenant isolation inside the Spring Boot applications.
If teams assume the mesh alone solves all security concerns, they usually end up with a false sense of safety and application-layer gaps that still matter.
I also consider overly broad authorization policies a serious design mistake. For example, using wide wildcards for paths, methods, or source identities may make initial rollout easier, but it weakens the purpose of zero trust.
If every authenticated service can still talk to almost every other service, the environment may be encrypted, but it is not truly following least-privilege principles. Good zero-trust design requires access boundaries to be explicit and intentional.
Another issue I have seen conceptually is poor service account hygiene. In a mesh-based model, workload identity matters a lot.
If teams use shared service accounts carelessly, mismatch service accounts across environments, or fail to align deployment identity with policy definitions, access rules become difficult to reason about. This usually leads to either unexpected denial of valid traffic or pressure to loosen policies too much just to keep systems running.
One more anti-pattern is forgetting non-obvious traffic paths. Teams usually think about direct API calls first, but real platforms also contain health probes, scheduled jobs, async consumers, startup dependencies, actuator traffic, and internal admin flows.
If those are not included in the rollout plan, authorization policies may appear correct on paper while still breaking important operational behavior in runtime.
The final mistake is underinvesting in observability. Without good proxy logs, metrics, traces, and policy visibility, teams often struggle to distinguish between an application defect and a mesh-layer denial.
That confusion slows down adoption and makes zero trust feel harder than it actually is. In my view, observability is not optional support tooling here. It is part of the architecture.
Common Anti-Patterns to Watch For
Enabling strict mTLS before all workloads are mesh-ready.
Treating service mesh as a replacement for application-layer security.
Using wildcard-heavy authorization rules that are too broad.
Ignoring service account and workload identity discipline.
Forgetting background jobs, async flows, probes, and internal admin traffic.
Rolling out policies without enough monitoring and debugging support.
Short Conclusion
Building a zero-trust service mesh for Spring Boot microservices is not just about adding encryption between services. The real value comes from making internal communication intentional, identity-driven, and policy-controlled instead of relying on broad trust inside the cluster.
When mutual TLS, workload authorization, application-level validation, observability, and operational discipline all work together, the platform becomes both more secure and easier to manage at scale.
What I found most important in this approach was the separation of responsibilities. The service mesh handled secure service identity and communication boundaries, while the Spring Boot applications continued to own business rules, user permissions, and tenant-specific validation.
That balance made the architecture more practical because it improved security without forcing every service to carry the same low-level transport concerns in code.
In the end, zero trust was not just a security enhancement. It also made the system easier to reason about.
Service interactions became more explicit, access assumptions became visible, and the platform became better prepared for growth, failure handling, and controlled production operations.
Future Enhancements and Next Steps
If I were taking this design further, the next step would be to move from a strong foundational zero-trust setup into a more automated and adaptive security model. Once mutual TLS, workload identity, authorization policies, and observability are all working reliably, the real opportunity is to reduce manual effort and make the platform smarter about how trust is managed over time.
That is where future enhancements become very valuable.
One natural next step would be deeper policy automation. Instead of defining every service authorization rule manually, platform teams can start building reusable policy templates aligned to service types, namespaces, environments, and ownership boundaries.
That makes the model easier to scale because security policy becomes part of platform standards instead of being recreated from scratch for each microservice. In larger environments, this can significantly reduce policy drift and inconsistency.
Another strong enhancement would be integrating policy validation directly into CI/CD workflows. Before new services or policy changes are deployed, automated checks can verify that service identities are correct, required mTLS settings are present, and authorization changes are not broader than intended.
This moves zero trust closer to a preventive model where mistakes are caught before they reach runtime.
I would also see value in expanding observability into more security-aware monitoring. For example, tracking unusual service communication patterns, sudden spikes in denied requests, or unexpected changes in workload identity usage can provide early signals that something has changed in the environment.
Over time, this creates a stronger feedback loop between platform operations and security posture.
If the platform were multi-region or global, another future enhancement would be extending the same trust model consistently across regions and clusters. That includes identity federation, policy consistency, secure failover, and region-aware service communication governance.
Zero trust becomes even more important in those environments because operational complexity increases with scale.
At the application layer, future work could also include tighter integration between workload identity and business telemetry. For example, correlating service identity, tenant scope, user context, and trace data can make security investigations and production debugging much more precise.
This is especially useful in systems with heavy internal API traffic and multiple layers of orchestration.
Overall, the next phase after initial implementation is really about maturity. The foundation secures communication, but the future enhancements make the model easier to govern, safer to evolve, and more practical to operate as the platform grows.
Possible Future Enhancements
Policy templates for standard service communication patterns.
CI/CD validation for mesh configuration and authorization policies.
Security-aware observability for unusual internal traffic behavior.
Cross-cluster and cross-region trust model standardization.
Better integration between identity, tracing, and tenant-aware diagnostics.
Gradual movement toward more automated policy governance.