Designing Production-Ready AI Agents with MCP, FastAPI, and LangChain !!!
Why Most Enterprise AI Agents Fail Before They Reach Production
A lot of AI demos look impressive in isolation. A chatbot answers questions, a tool-calling agent fetches data, or a retrieval pipeline summarizes internal documents.
But the real difficulty starts when we try to move these ideas into a production environment.
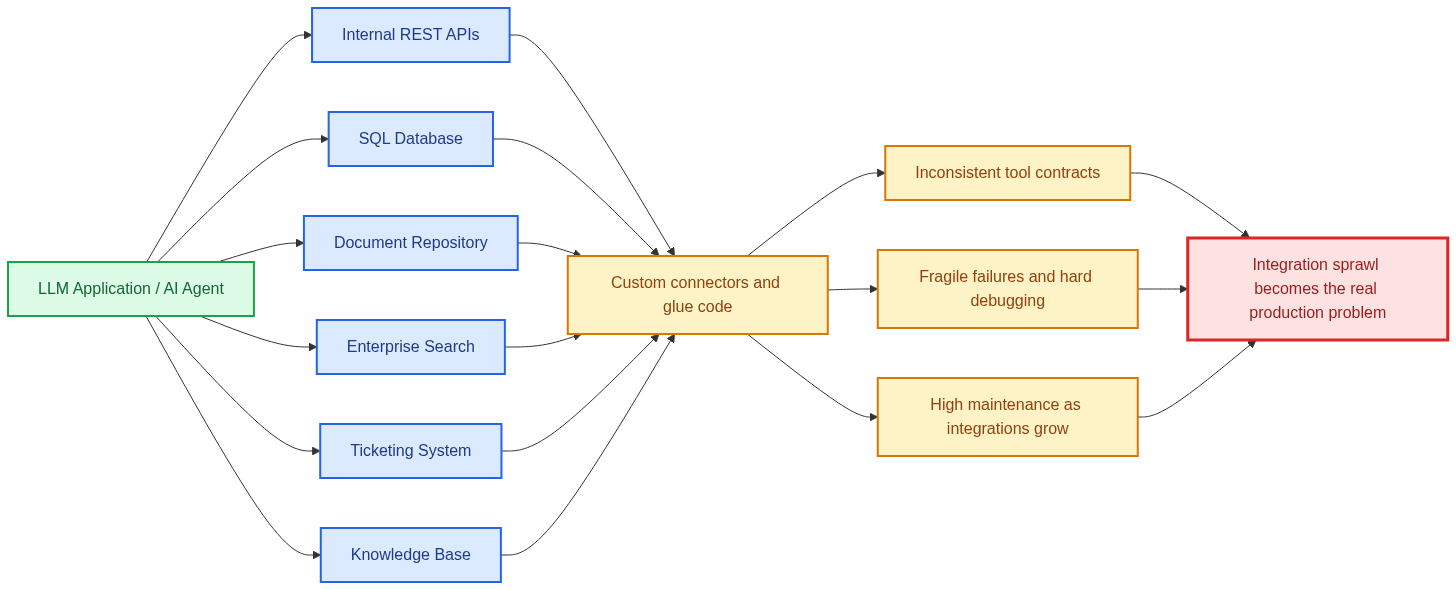
In an enterprise setting, an AI agent rarely interacts with just one clean, well-defined data source. It usually needs to work across internal APIs, document repositories, ticketing systems, databases, knowledge bases, and operational tools.
Each of these systems has its own authentication model, schema, latency behavior, error patterns, and ownership boundaries. Very quickly, what started as a simple LLM integration becomes an orchestration problem.
This is where many teams begin accumulating glue code. One connector is written for a document store, another for an internal REST service, another for a SQL database, and yet another for a search backend.
Soon, the application logic becomes tightly coupled with tool-specific integration logic. That coupling makes the system harder to evolve, harder to test, and much harder to scale safely.
The bigger issue is not just complexity. It is inconsistency.
Different tools expose capabilities differently. Some return structured JSON, some return raw text, some fail noisily, and some fail silently.If an agent framework has to understand every tool in a custom way, then reliability becomes fragile. Even small changes in one downstream system can create surprising failures in the agent layer.
This is exactly the kind of problem that architecture should solve early. If we treat every new enterprise tool as a one-off integration, the AI platform becomes a patchwork of adapters.
But if we introduce a standard interaction model between the LLM application and enterprise tools, we get a cleaner contract, better reuse, and a more maintainable path to production.
That is where Model Context Protocol, or MCP, becomes interesting. MCP is not just another AI buzzword.
It is useful because it gives us a standard way to expose tools and context to language models and agent-based applications. Instead of baking every integration directly into the agent, we can separate the concerns more cleanly: the agent handles reasoning and orchestration, while MCP-compatible services handle tool exposure in a consistent format.
In this blog, I will walk through how MCP, FastAPI, and LangChain can be used together to build a production-oriented AI agent architecture. The focus is not on toy examples.
The focus is on creating a system that is easier to extend, easier to observe, and safer to operate in a real engineering environment.
In the next section, I will explain what MCP actually is, why it matters, and how it changes the integration model for enterprise AI systems.
What MCP Actually Solves
At this point, the natural question is: what exactly does MCP solve that normal APIs do not?
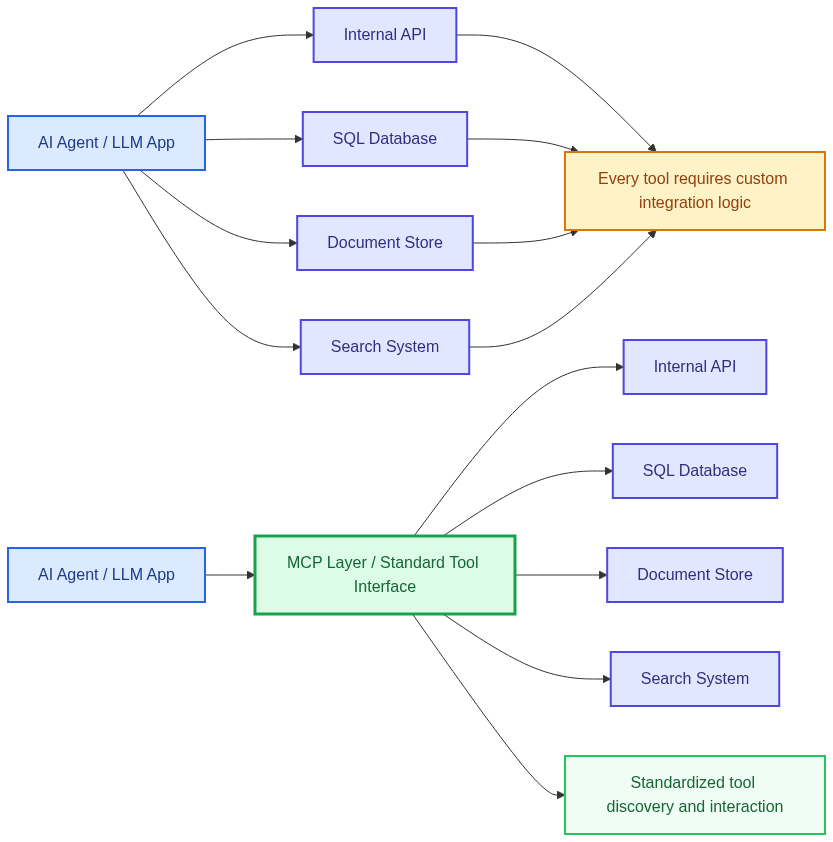
The short answer is that MCP gives AI applications a standardized way to discover and use tools, resources, and context. In a traditional enterprise integration model, every agent or LLM-powered application needs custom logic to understand how each tool works.
One system may expose a REST endpoint, another may require a database query, and another may return unstructured content from a document repository. The integration works, but every new connection adds more custom behavior into the application layer.
MCP changes that model by introducing a more uniform interaction contract. Instead of forcing the AI application to directly understand the implementation details of every backend system, MCP allows those capabilities to be exposed in a consistent and machine-friendly way.
That consistency matters because language-model-based systems are not just calling tools. They are reasoning about which tool to use, when to use it, and how to interpret the result.
From an architecture point of view, MCP creates a cleaner separation of concerns. The agent framework can focus on planning, orchestration, and response generation.
The MCP layer can focus on exposing enterprise capabilities in a structured, discoverable, and reusable format. Backend systems can continue to do what they already do well, without leaking too much system-specific complexity into the agent itself.
This may sound like a small design improvement, but in production systems it becomes a major advantage. A standard tool interface reduces duplication, improves maintainability, and makes it easier to evolve the platform over time.
Instead of rewriting integration logic for each new agent use case, teams can build reusable MCP-compatible services once and let multiple AI applications consume them.
Another important point is that MCP does not replace backend services. It sits between the agent layer and enterprise systems as a standard interface for exposure and interaction.
That means it fits naturally into modern service-oriented environments. If your organization already has APIs, search systems, data stores, and internal platforms, MCP can act as the normalization layer that makes those systems easier for AI agents to consume.
This is the main reason MCP is becoming relevant in enterprise AI architecture. It is not only about connectivity.
It is about making tool usage more predictable, extensible, and operationally manageable.
In the next section, I will show how FastAPI, LangChain, and MCP fit together in a practical production-oriented architecture.
How FastAPI, LangChain, and MCP Fit Together
Now that the role of MCP is clearer, the next step is to understand how FastAPI and LangChain fit into the same architecture.
A simple way to think about it is this: LangChain can help orchestrate the agent workflow, FastAPI can expose services in a lightweight and developer-friendly way, and MCP can define a standardized interface between the agent and the tools it wants to use. These three pieces are not competing with one another.
They solve different parts of the problem.
LangChain sits closest to the agent behavior. It helps manage prompts, tool invocation, chaining, routing, and interaction patterns with language models.
If the system needs an agent to decide whether to query a document source, call a business API, or fetch structured data, LangChain can help coordinate that decision-making flow.
FastAPI is useful on the service side. It provides a clean way to expose backend functionality through HTTP endpoints and is especially convenient for AI-adjacent services because of its simplicity, async support, and strong developer ergonomics.
In this kind of setup, FastAPI can be used to implement MCP-compatible service endpoints or supporting APIs that sit behind the MCP layer.
MCP becomes the contract layer between the agent and those backend capabilities. Instead of the agent directly dealing with every backend implementation detail, MCP standardizes how tools and resources are described and invoked.
This keeps the orchestration layer cleaner and makes the system easier to extend.
Architecturally, this creates a nice separation. LangChain handles agent reasoning.
MCP handles standard tool exposure. FastAPI helps implement the actual services that expose those capabilities.Enterprise systems such as search platforms, databases, internal microservices, and document repositories remain behind that layer, continuing to serve their own business purpose.
This structure is valuable because it avoids tightly coupling the agent to backend-specific logic. If a team wants to add a new tool later, they do not need to rewrite the whole orchestration model.
They can expose the capability through the MCP layer, and the agent can discover or use it through a more consistent interface.
In production, this also improves maintainability. Teams can evolve the backend services independently, keep the agent layer relatively stable, and enforce clearer boundaries for ownership, testing, and observability.
In the next section, I will move from the conceptual view to a production-ready request flow and show what happens when a user query travels through this architecture.
What a Production Request Flow Looks Like
So far, the architecture has been described at a conceptual level. The next step is to understand what actually happens when a real user query enters the system.
Let us say a user asks a business-focused question through a client application. That question could be something like asking for a customer summary, requesting the latest support issues for an account, or searching for information across enterprise documents and operational systems.
From the user’s point of view, it looks like a single AI-powered interaction. But behind the scenes, several layers may participate before a reliable answer is returned.
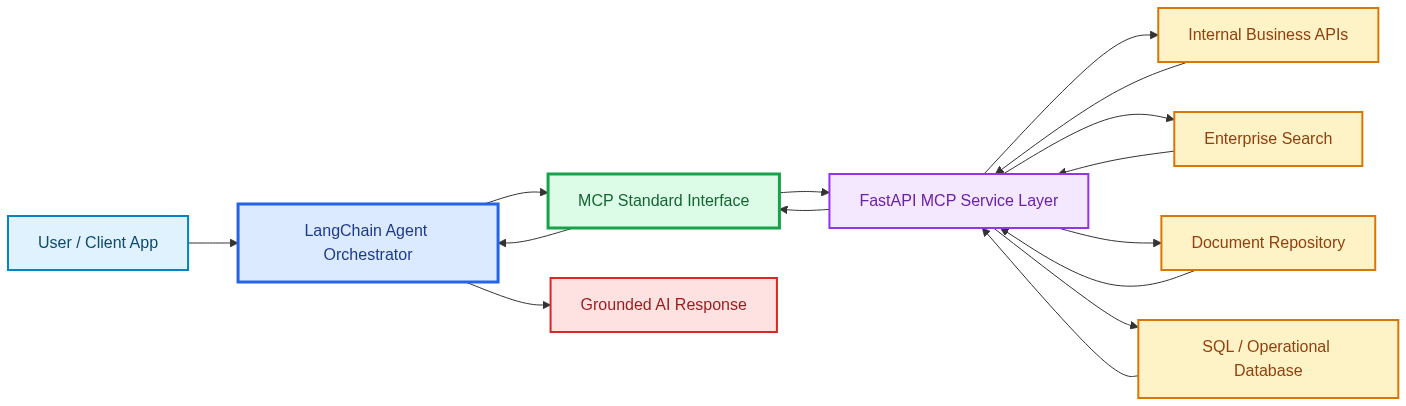
The request first reaches the agent orchestration layer. This is where the system interprets the query, determines intent, and decides whether external tools are needed.
Not every user request should trigger tool usage. Some questions can be answered directly, while others need fresh data, document retrieval, or business-system lookups.
If the query needs external context, the orchestration layer interacts with the MCP interface. This is a key design choice because the agent does not directly hardcode itself to every backend system.
Instead, it uses the MCP layer as a standardized gateway for discovering and invoking the right capabilities.
The MCP-enabled service layer then routes the request to the appropriate backend source. That might mean calling an internal API, running a database lookup, retrieving content from a document repository, or querying enterprise search.
At this point, the architecture behaves much more like a controlled tool-execution pipeline than a simple chatbot.
Once the backend systems return their data, the service layer sends structured results back through the MCP interface to the agent. The agent then uses that information to compose a grounded response.
This step is important because the final answer is no longer based only on the model’s prior knowledge. It is shaped by live or enterprise-specific context retrieved during execution.
In a production environment, this flow also creates better control points. Each layer can be observed, logged, tested, and evolved independently.
Teams can track which tools were called, how long they took, whether fallbacks were triggered, and how reliable the overall request path is over time.
That is the practical value of this architecture. It turns AI interaction into a manageable request pipeline instead of an opaque black box.

In the next section, I will focus on what makes this architecture production-ready beyond the happy path, especially observability, failure handling, and maintainability.
What Makes This Architecture Production-Ready
A good architecture is not defined only by how well it works when everything goes right. In production, the real test is how the system behaves when dependencies are slow, data is incomplete, tools fail unexpectedly, or traffic patterns change.
That is where many AI applications struggle. They may perform well in demos, but they become difficult to trust once they are exposed to real-world conditions.
This is why production readiness matters as much as model quality. If an AI agent is expected to answer business-critical questions or interact with enterprise systems, it needs to operate inside a framework that supports reliability, visibility, and controlled behavior under failure.
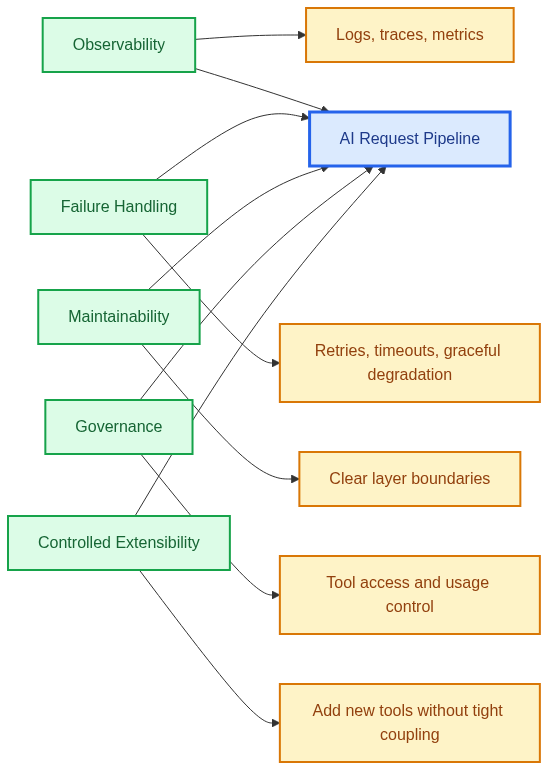
Observability is one of the first requirements. Teams need to know which user queries triggered tool usage, which tools were invoked, how long each step took, what inputs and outputs were exchanged, and where failures occurred.
Without that visibility, debugging becomes guesswork. With proper observability, the AI flow becomes inspectable in the same way modern distributed systems are.
Failure handling is equally important. Not every backend system will respond quickly or consistently.
Some requests may time out. Some tools may return incomplete or low-quality data.Some dependencies may be temporarily unavailable. A production-ready design should anticipate these situations by supporting retries, fallbacks, timeouts, and graceful degradation. In many cases, it is better to return a partial but transparent answer than to fail silently or generate an overconfident response.
Maintainability also becomes a core architectural concern. As more tools are added, the system should not become harder to understand or operate.
This is where the separation between orchestration, MCP-based tool exposure, and backend services becomes valuable. It allows different parts of the system to evolve without creating unnecessary coupling across the entire stack.
Another important factor is governance. In enterprise environments, teams often need clear control over which tools the agent can access, how those tools are invoked, and how usage is monitored.
A structured architecture makes these controls easier to apply. It also creates a better foundation for policy enforcement, cost awareness, and operational review.
In other words, production readiness is not one feature. It is the combination of traceability, resilience, operational clarity, and controlled extensibility.
That combination is what turns an AI prototype into a dependable enterprise system.
In the next section, I will show how this architecture can evolve as more tools and use cases are introduced without turning into another tightly coupled integration mess.
How the Architecture Scales Without Becoming Another Integration Mess
One of the biggest risks in enterprise AI is that the first successful use case creates a wave of new requests. Once one team sees value in an AI-powered workflow, other teams want the same thing.
They want new tools connected, new business domains exposed, new data sources onboarded, and new agent behaviors introduced. This is usually the point where an initially clean solution starts becoming messy again.
That is why scalability in this context is not only about traffic or throughput. It is also about architectural scalability.
The system should be able to support more tools, more use cases, and more teams without forcing every change back into one tightly coupled codebase.
This is where the separation between orchestration, MCP-based tool exposure, and backend services becomes especially useful. If a new capability needs to be introduced, the team does not have to modify the entire agent application in deeply coupled ways.
Instead, they can expose the new capability through the MCP layer using the same general interaction model already established for other tools.
That approach creates a more modular path for growth. Different teams can own different tool implementations.
One team may expose a search capability, another may expose document retrieval, and another may provide access to a business workflow API. As long as those capabilities are surfaced through a consistent interface, the orchestration layer can remain much more stable.
This also improves the development model. Teams can iterate on their services independently, test them within clearer boundaries, and onboard new use cases faster.
The architecture becomes closer to a platform model rather than a one-off application. That shift is important because enterprise AI rarely stays limited to a single use case for long.
Another benefit is that the system becomes easier to reason about operationally. When a new tool is added, the impact is more localized.
Observability, testing, and governance can be applied at the service boundary instead of being buried inside a growing set of custom connectors scattered across the codebase.
In effect, this architecture scales by encouraging reuse and standardization rather than duplication. That is what prevents the next generation of AI integrations from becoming the same kind of maintenance burden that many enterprise API landscapes already suffer from.
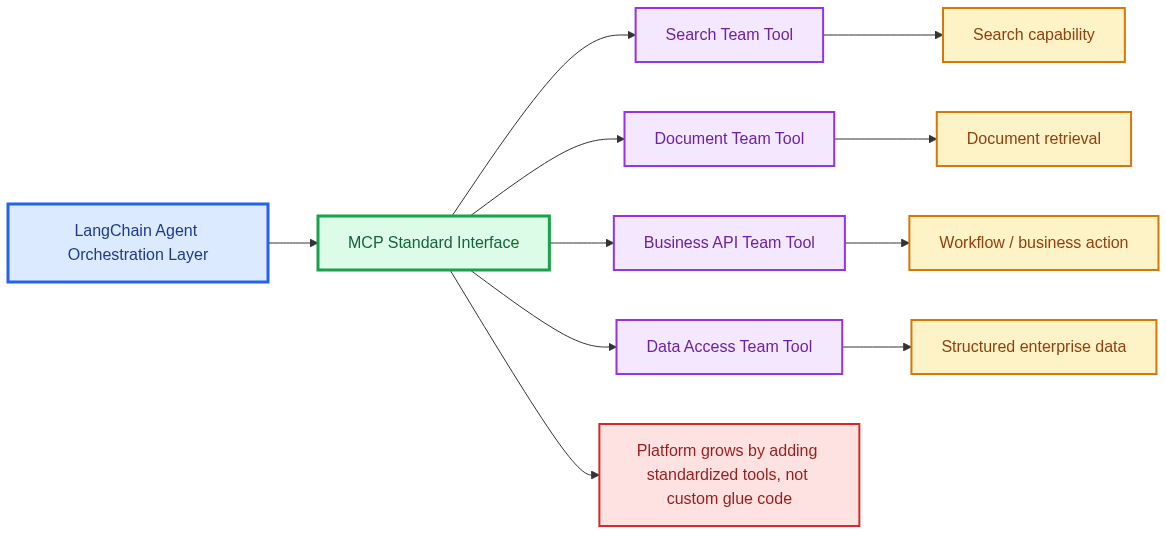
In the next section, I will bring everything together with a practical example of how an enterprise team could start small and evolve this architecture incrementally.
Start Small and Evolve the Architecture Incrementally
One reason many enterprise AI initiatives slow down is that teams try to design the final platform before proving the first useful workflow. That usually leads to overengineering, unclear ownership, and a lot of discussion before any real value is delivered.
A better approach is to start with one focused use case and evolve the architecture step by step.
For example, a team might begin with a single high-value workflow such as answering customer-support questions using internal documentation and one business API. That first version does not need to solve every enterprise AI problem.
It only needs to prove that the orchestration layer, MCP-based tool access, and backend integrations can work together in a controlled and observable way.
Once that first use case is stable, the team can improve the surrounding platform incrementally. They may add better logging, stronger failure handling, more structured tool definitions, and clearer operational dashboards.
After that, they can onboard a second and third tool, gradually expanding the architecture without changing its core shape.
This incremental model is important because it reduces both technical and organizational risk. Teams learn where the actual complexity is.
They identify which tools are genuinely useful, which workflows need tighter controls, and where latency or failure patterns show up in practice. That feedback is much more valuable than trying to guess everything upfront.
It also helps with ownership. The initial implementation can be owned by a small team, but as the platform proves useful, other teams can begin contributing MCP-compatible tools or services.
That way, the architecture grows through collaboration and standardization rather than through one central team building every connector manually.
Over time, the system starts looking less like an experiment and more like a reusable internal AI platform. But that maturity comes from steady iteration, not from attempting to solve every requirement in the first release.
That is probably the most practical lesson in this architecture. Start narrow, make the path observable, standardize tool access early, and expand only after the first workflow is delivering value reliably.

In the next section, I will close with the main architectural takeaways and why MCP, FastAPI, and LangChain form a strong foundation for production-ready AI systems.
Final Thoughts
Designing AI systems for production is not only about choosing a capable model. It is really about building the right surrounding architecture.
The moment an AI application needs to interact with enterprise tools, live data, internal APIs, and operational systems, the problem becomes much broader than prompt engineering.
That is why standardization matters so much. If every tool is integrated differently, the agent layer becomes fragile, difficult to maintain, and harder to scale.
But when tool access is exposed through a more consistent interaction model, the overall system becomes easier to reason about and much more adaptable over time.
This is where MCP becomes valuable. It helps define a cleaner contract between AI applications and enterprise capabilities.
LangChain fits naturally into this picture by supporting orchestration and agent behavior, while FastAPI provides a practical way to implement lightweight service endpoints around those capabilities. Together, they form a strong foundation for building AI systems that are not just functional, but operationally manageable.
The bigger architectural lesson is that enterprise AI should be treated like any other serious distributed system. It needs observability, failure handling, ownership boundaries, and a path for controlled evolution.
The teams that recognize this early will build systems that are easier to trust and easier to expand.
A good starting point is not to build everything at once. Start with one useful workflow, make it observable, standardize how tools are exposed, and then grow the platform in a deliberate way.
That approach creates a much better path to long-term success than rushing into a large but tightly coupled implementation.
In the end, the goal is not just to connect an LLM to a few tools. The goal is to create an architecture that allows intelligent systems to operate reliably in real business environments.
That is the difference between an interesting demo and a production-ready AI platform.
